
📌 Key Takeaways
Clean, organized buying records matter more than any AI tool you could buy.
- Fix Your Supplier List First: When the same supplier appears under three different names, every spending report and price comparison starts wrong.
- Messy Records Break AI Fast: Tools can’t reliably compare quotes when product names, prices, and terms are scattered across inboxes and mismatched spreadsheets.
- Start Small, Start Now: Pick one active product category, clean those records for the last three to six months, and build from there.
- Someone Must Own the Data: Cleanup fades fast when everyone uses the records but no one is responsible for keeping them accurate and up to date.
- Tools Come Last, Not First: Buying software before your data is consistent just automates the mess — organized records first, tools second, results third.
Organized data is the real starting line — everything else is just noise without it.
Procurement leaders and buyers at growth-stage paper trading SMBs will gain a clear cleanup sequence here, preparing them for the detailed overview that follows.
~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~
While AI can assist in parsing and structuring messy text, it generally cannot rescue fundamentally unclear buying records without a high risk of error.
The quote spreadsheet has 14 tabs. Three belong to a team member who left last year, and the column headers stopped matching somewhere around tab six. Meanwhile, leadership wants smarter procurement decisions—faster supplier comparisons, clearer spend visibility, less guesswork on reorders.
If your procurement knowledge lives in one team member’s inbox and another’s memory, you are not alone. Most growth-stage paper trading SMBs hit this wall. The interest in AI is real. The primary bottleneck is rarely financial or technical; it is the fragmentation of procurement data across siloed inboxes, unlinked spreadsheets, and unreconciled supplier quotes.
After working through the checklist below, you will know exactly which procurement records need organizing, where the messiest gaps hide, and what to clean first — before spending a dollar on tools. That clarity is the actual starting point for preparing procurement data for AI.
What “AI-ready Procurement Data” Means
AI-ready procurement data is buying information that is organized, consistent, findable, and connected to real decisions. It is not a software certification or a technology standard. It represents a state of operational readiness where supplier identities, historical quotes, and product specifications are sufficiently structured to be ingested by any computational workflow.
The practical test comes down to a few questions. Can your team compare quotes from different suppliers without manually reconciling inconsistent formats? If not, understanding why paper RFQs are hard to compare manually is a useful starting point. Can you pull a supplier’s history and see what was purchased, when, at what price, and under what terms? Is your procurement process mature enough that a new team member could find and trust the records without asking three colleagues?
For paper trading SMBs, this is mainly a comparability problem. A supplier in your quote log should match the same supplier in your purchase records — a comparability step explored further in our guide, how to standardize paper supplier quotes before using AI to compare them. A product description should use the same core attributes across quotes. A purchase order should connect supplier, product, quantity, price, and date in a way that your procurement, finance, and operations teams can follow.
Procurement process maturity, in simple terms, means your buying workflows are repeatable, your records use agreed terms, and someone is responsible for keeping them that way. While machine learning tools are frequently used to identify and merge duplicated entries, AI cannot reliably reason over records that are fundamentally incomplete or trapped in inaccessible inboxes. Readiness is operational, not technical.
That principle is consistent with broader data-quality thinking. The W3C Data on the Web Best Practices emphasizes data that is understandable and usable by consumers, while the NIST AI Risk Management Framework offers general guidance for organizations developing, deploying, or using AI systems. These sources do not make paper-procurement claims. They support the general idea that useful technology depends on usable inputs.
The AI Procurement Data Readiness Checklist
Use this checklist as a working assessment, not a compliance test. Product fields vary by company, product family, and supplier quoting format. Treat the examples below as general principles unless your internal item master, supplier quote format, or procurement team confirms them.
For a hypothetical example, consider a paper trading SMB buying coated and uncoated grades from eight suppliers across two regions. If the same supplier appears as “Eastern Paper Co.,” “Eastern Paper,” and “E. Paper Co Ltd” across different files, every comparison built on those records starts on shaky ground.
| Data area | What to check | Why it matters | Readiness signal | Cleanup priority |
| Supplier master data | Look for duplicate names, outdated contacts, payment terms if available, and active or inactive status. | Supplier views become unreliable when one supplier appears under several names. | Procurement and finance use the same approved supplier name. | High — start here |
| Quote history | Check whether quotes include supplier, date, product, quantity, unit, currency, relevant attributes, freight terms, and validity where available. | Quote comparison weakens when price is separated from context. A price without freight terms, validity window, or volume tier loses meaning when stacked against another. | Recent quotes can be searched and compared without opening old email threads. | High |
| Purchase records | Confirm whether POs or purchase logs connect supplier, product, quantity, price, and order date. | Purchase history shows what was actually bought, not only what was offered. This is the backbone of spend analysis. | A buyer can trace a purchase back to a supplier and product record. | High |
| Product attributes | Review whether descriptions are structured enough to compare like-for-like products — relevant attributes such as grade, size, weight, finish, or whatever fields your team uses. | Paper products with similar names may not be commercially comparable. Inconsistent descriptions lead to comparing the wrong products. | The team uses agreed fields such as grade, size, weight, finish, or the attributes relevant to its own catalog. | High |
| Email-to-system workflow | Check whether supplier quotes and updates stay in email or move into a shared record. | Email is useful for discussion, but weak as a reusable buying database. Information trapped in email is invisible to the rest of the team and to any future analysis. | Every new quote has a defined place to be recorded, following a repeatable quote-to-order workflow. | Medium |
| Spreadsheet structure | Check version control, inconsistent columns, duplicate tabs, free-text fields, and unclear formulas. | Spreadsheets fail when every buyer maintains a different version. When three versions of a quote log exist on three laptops, which one is current? | One current file or controlled export is treated as the working record, with consistent headers and a named owner. | Medium |
| Data ownership | Identify who updates each record and who checks quality. | Data cleanup fades when everyone uses the records but no one maintains them. Without clear ownership, records decay and cleanup becomes nobody’s job. | Each important data area has a named owner. | High |
If your team wants to go deeper on quote fields, ‘standardizing paper supplier quotes before using AI’ is a useful next read. For quote evaluation, our article ‘AI-assisted quote comparison for paper buyers’ explains why unit price alone is not enough for reliable comparison.
Do not try to clean everything first. Start with the most active suppliers, the most recent three to six months of quote history, and your highest-volume product categories. Prioritizing current decision-support data ensures immediate ROI, whereas scrubbing legacy archives for discontinued lines offers diminishing returns.
Where Messy Procurement Data Usually Breaks AI Usefulness
Messy procurement data breaks when the business tries to compare things that are not recorded consistently.
Duplicate supplier records distort the picture. Here is an illustrative example, not a case study. One buyer records a supplier under its full legal name. Another shortens the name in the quote spreadsheet. Finance uses a supplier code from the accounting system. The inbox contains quotes from a sales contact whose email signature uses a slightly different trading name. A person may recognize the connection. A tool may not unless the relationship is mapped. A buying analysis might show two “small” suppliers instead of one significant one — missed leverage that compounds over time.
Product descriptions create the same problem. One quote says “white printing paper 70 GSM.” Another says “maplitho 70g white.” A third includes size, packing, and delivery terms. This kind of specification mismatch is exactly what makes AI-assisted quote comparison unreliable without normalization first. Depending on your product catalog, those may or may not be comparable offers. If the record does not carry the fields your team uses to decide, the comparison becomes a judgment call hidden inside a spreadsheet cell. To see how deep this comparison problem runs, ‘why paper RFQs are hard to compare manually’ walks through the specific fields that create misalignment.
Email-based quotes add another layer of damage. A supplier may send an updated offer at 5:43 p.m., after the buyer has already copied the earlier quote into a spreadsheet. If the revised price, validity, or freight term remains buried in the thread, your shared record is already out of date. Over months, institutional knowledge about supplier relationships and pricing trends ends up living in people’s heads rather than in shared records — a problem that compounds when unstructured price history prevents any meaningful trend analysis. That is a business risk — if that buyer leaves, the knowledge leaves too.
Treating incomplete data as reliable, or worse, automating a broken workflow, just accelerates the problems.
A Practical Cleanup Sequence Before Evaluating AI Tools
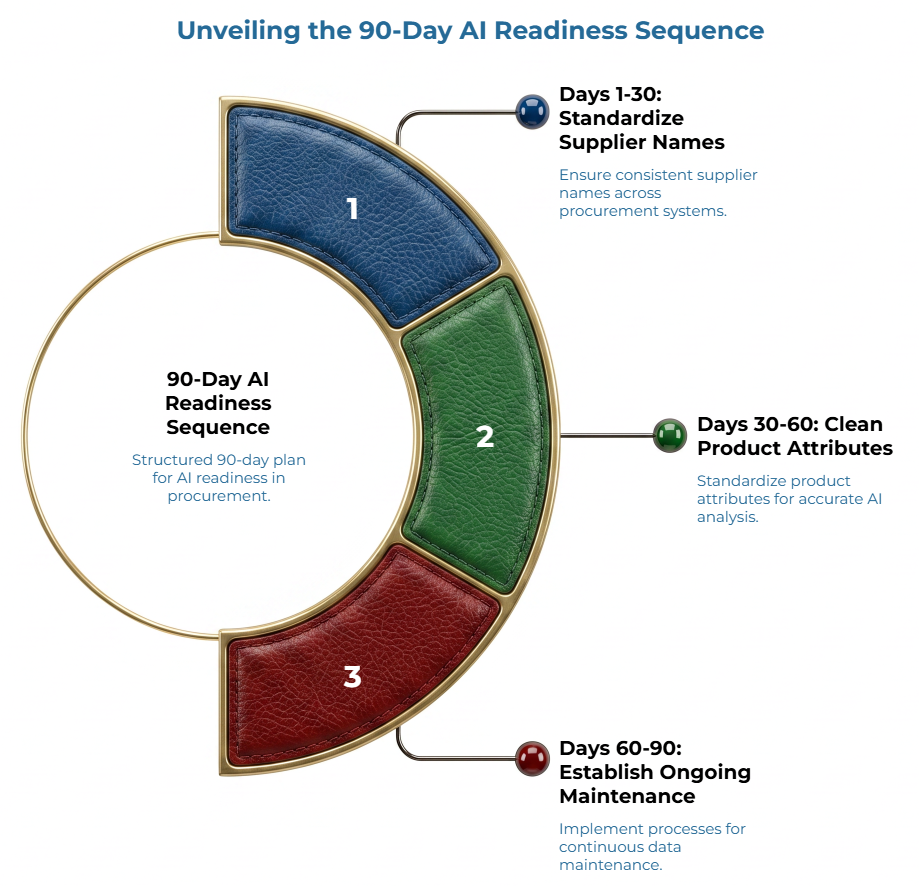
To make this cleanup actionable without stalling daily operations, execute the strategy in a tight, 90-day rolling sequence focused entirely on upcoming transactional decisions.
First 30 days: Choose one procurement category or product family. Pick something active enough to matter but narrow enough to finish — a recurring paper grade, a common packaging paper item, or a product family with frequent supplier quotes. Then standardize supplier names within that category. Create one approved name for each active supplier and map common variations to it. This can begin in a simple controlled supplier list. The point is not software sophistication. The point is that procurement, finance, and operations stop splitting the same supplier into several records. Next, consolidate recent quote history into a shared file or system where it can be searched by supplier, product, and date. If you need a model for what consistent quote fields look like, the guide on standardizing paper supplier quotes before using AI to compare them is a practical starting point.
Days 30–60: Clean the most-used product attributes. Use whatever attributes your team needs to compare with like — grade, GSM, sheet size, finish, packing, delivery terms, or other variables your buyers rely on — and make sure those fields are filled in consistently. For teams unsure which fields matter most, ‘how AI can help paper buyers catch specification gaps’ offers a practical 10-area framework. Then match recent purchases to suppliers and products so you can see what was actually ordered, from whom, and at what cost — the kind of traceability that makes paper specification matching far more reliable. Purchase records are the reality check. They show what was bought, not just what was quoted.
Days 60–90: Decide where new quotes and orders should be recorded going forward. This does not require new software. It requires a clear agreement about where records go and in what format. Then assign an owner for ongoing updates. Cleanup without maintenance is a temporary fix.
This is a minimum viable approach, not a full transformation. Avoid buying software before defining the workflow, and avoid expecting AI to clean the data unsupervised.
Common Mistakes To Avoid
Buying AI tools before defining the data foundation is the most obvious mistake. A tool’s utility is capped by the integrity of its source data; high-order automation cannot compensate for low-order record keeping. This is why understanding how paper buyers can use AI to track price signals only becomes practical once quote records are consistent.”
Treating spreadsheets as the problem is another shortcut. Spreadsheets can work when they are structured, current, and owned. They become a problem when each buyer keeps a separate version, columns change without review, or formulas are unclear.
Boiling the ocean by scrubbing legacy archives is a major pitfall. Focus exclusively on active transactional pipelines; historical records for discontinued lines or defunct vendors yield diminishing operational returns.
The quietest mistake is ignoring ownership. Data ownership means someone is responsible for keeping a record usable after the first cleanup. Without that role, your supplier list, quote log, and product fields will drift again.
Who Should Own Procurement Data Readiness?
Procurement should usually own the buying context. Buyers understand supplier relationships, quote meaning, and the product attributes that affect comparison. They know when two offers look similar but are not actually comparable.
Finance should support spend, payment, supplier code, and accounting-export alignment. Operations or inventory should support product and stock context, especially when product descriptions affect receiving, storage, or fulfillment. Leadership plays a critical role in defining priorities and creating accountability — without a decision from someone with authority, cleanup stalls.
IT or systems support may help with exports, access, templates, or workflow setup. Still, procurement data readiness should not be treated as only an IT issue. The work crosses teams because the records are used across teams.
A simple ownership rule is enough to start: every key record needs one accountable owner and a review rhythm. No committee. No heavy governance language. Just clarity.
When Your Data Is Ready Enough To Explore AI-enabled Workflows
You are ready to explore AI-enabled procurement workflows when the core records are consistent enough to support a useful comparison. Ready enough does not mean flawless. It means the data is structured, current, and trusted for the decision at hand.
Use these signs as a practical threshold:
- Supplier names are reasonably consistent across procurement and finance records.
- Recent quote history can be searched and compared across your most active product categories.
- Purchase records connect supplier, product, quantity, price, and date.
- Key product attributes are structured enough to compare like with like.
- New quotes follow a repeatable recording process.
- Someone owns ongoing maintenance for each major data area.
If several of these are missing, pause before tool evaluation. Map the records first. The result may be a clearer spreadsheet, a better shared folder, a revised quote log, or a later software decision. The right answer varies by company size and workflow.
For teams still comparing supplier responses manually, why paper RFQs are hard to compare manually gives useful context for the quote-normalization problem.
Frequently Asked Questions
Can AI help if procurement data is still in spreadsheets?
Yes, spreadsheets can be a starting point if they are structured, consistent, and maintained. They are how most growth-stage SMBs manage procurement, and that is completely normal. The key factors are consistency, structure, and maintenance. Messy or conflicting spreadsheets with duplicated tabs, unclear formulas, and important quote context buried in free-text notes will limit the usefulness of any tool layered on top — a reality explored in depth in ‘the hidden cost of unstructured price history in paper procurement.’
What procurement data should be cleaned first?
Start with supplier records, recent quote history, purchase records, and product attributes tied to the most active buying categories. Clean the records your team uses every week before cleaning old archives. These give the most immediate return on cleanup effort.
Does an SMB need an ERP before using AI in procurement?
Not necessarily. The first requirement is usable, consistent data and a repeatable workflow for capturing new records — for example, following a consistent quote-to-order process that normalizes fields before comparison. An ERP or procurement platform may help in some situations, but buying software before defining the data foundation often creates new problems rather than solving existing ones. Harvard Business Review’s analysis of why data quality matters for AI reinforces this point: rigorous data architecture must precede the implementation of generative or analytical models.
Who should own procurement data quality?
Procurement should own buying context, with finance, operations, inventory, and systems support where relevant. The important point is named accountability. Shared responsibility without ownership becomes no responsibility.
When is a company not ready for AI in procurement?
When supplier records have significant duplicates, quote history cannot be searched or compared, product descriptions are inconsistent across records, and no one owns data quality. These are signals that foundational cleanup should come first.
Start With One Record Set
AI readiness sounds technical until you bring it back to the buying desk. The real question is simpler: can your team compare supplier, quote, product, and purchase records with confidence? For teams ready to take that step, PaperIndex Academy offers practical guides on standardization, quote comparison, and specification alignment.
Start by choosing one active product category and reviewing whether those records are consistent enough to compare. If they are not, fix that category first. One supplier list. One quote log. One product family. One owner.
Organized data first. Tools second. Results third.
Disclaimer:
This article is educational and does not constitute professional procurement, technology, or business advice. All examples used are hypothetical and illustrative. Readers should consult with qualified procurement or technology professionals for decisions specific to their business.
Our Editorial Process:
Our expert team uses AI tools to help organize and structure our initial drafts. Every piece is then extensively rewritten, fact-checked, and enriched with first-hand insights and experiences by expert humans on our Insights Team to ensure accuracy and clarity.
About the PaperIndex Insights Team:
The PaperIndex Insights Team is our dedicated engine for synthesizing complex topics into clear, helpful guides. While our content is thoroughly reviewed for clarity and accuracy, it is for informational purposes and should not replace professional advice.